| Proteus Structure Prediction Server |
| Comprehensive Secondary Structure Predictions |
| HOME | DOCUMENTATION | SAMPLE OUTPUT | CONTACT & DOWNLOAD |
|
|
||||
|
|
Proteus Help Proteus is a web server that allows prediction of secondary structure and tertiary structure with a high degree of accuracy, without the user having any prior knowledge of the structure of the protein.
How to use Proteus Proteus takes as input a FASTA file or raw sequence data, and you can either upload a file that is stored on your computer containing the data, or paste the file directly into the entry box.Email options You may also specify if you want the results emailed to you, or you can choose to watch a live progress report of your prediction. Due to the length of time that the prediction requires, it is recommended that you use the email option. Please note that if you do choose to use the email option, you will receive a link to a results page, not the results themselves.Method options Proteus uses a "Jury of Experts" approach involving predictions from PSIPRED ( Jones, 1999 ), JNET ( Barton et al., 1999 ), TRANSSEC (a locally developed tool). You can choose to run one of these methods, or all of them using the "jury or experts" approach. Using all methods will have the highest accuracy, but will also be the slowest.Output Proteus will output the following items:
H = Helix How Proteus measures up
How Proteus works Proteus is comprised of three separate processes that combine to produce the final output. Click here to see a flow chart.Methods
The prediction method described here is split into four stages: (1) An initial homolog search to determine if
part or all of the sequence is homologous to a known structure. (2) A prediction by all three of the consensus
prediction methods, which are then fed as inputs into a neural network, which then (3) combines these
predictions to make a prediction of its own. The neural network's prediction and the results of the homology
search are then merged to produce the final prediction.
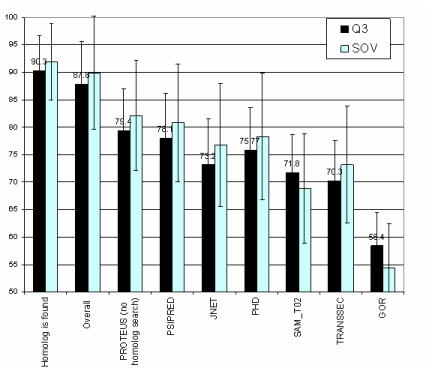
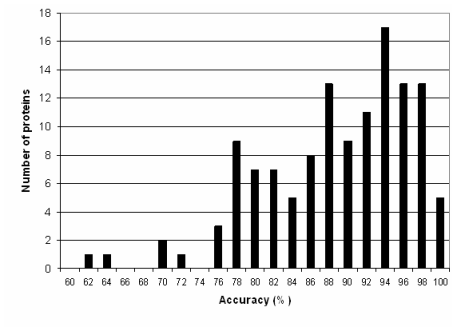
The independent prediction methods were chosen to have orthogonal prediction propensities, so as to maximize the effectiveness of a combined method. Lacking any formal way to judge a prediction method's effectiveness at predicting certain sequences, methods with orthogonal methods of prediction were used. PSIPRED is a two-stage neural network structure based on position-specific scoring matrices generated by PSI-BLAST, with an EVA accuracy of 77.8%. JNET uses HMM profiles generated from sequence alignments, position-specific scoring matrices, and a neural network, and has an EVA accuracy of 76.4%. A third method was devised as a tie-breaker, and is similar to the PHD approach, yet achieves about 72% Q3 accuracy. Given that all three methods used significantly different methods of prediction, it was hoped that the methods would produce significantly different results under similar circumstances. GOR, a fourth method based on information theory that was used initially, was discarded during development because its accuracy was significantly below the other methods. A database containing 8,679 non-redundant sequences and structures from the 2002 PDB database, filtered so as to remove any sequence with >30% sequence homology, was obtained as a training set for the neural network-based consensus method, and as the main database for the homology search. The structures contained in this database were also obtained from PDB, but verified so as to not contain "impossible" structures, such as sheets or helices containing a single residue, such as might be annotated using an automatic secondary structure annotation method such as DSSP. Homology searchUsing the non-redundant database described above, a homology search using BLASTP is performed, using an e-value of 1x10-7. Only the best result (smallest e-value) is retained. The structure for that sequence is then retrieved for merging with the predicted structure.Neural Network architectureThe methods and underlying theory to PSIPRED and JNET have been published previously and the programs were used as received without further modification. The TRANSSEC program was developed in-house using a Java-based neural network package known as Joone.TRANSSEC's underlying approach is relatively simple, consisting of a standard PSI-BLAST search integrated into a two-tiered neural network architecture. The first neural network operates only on the sequence, while the second operates on a 4 x N position-specific scoring matrix consisting of the secondary structure determined via the first network. The first neural net uses a window size of 19, and was trained on sequences from the PROTEUS-2D database (independent from those used in training the other neural nets). This neural net had a 399-160-20-4 architecture (21 x 19 inputs, 2 hidden layers of 160 and 20, and four outputs). The second neural network used a position-specific scoring matrix, combining evolutionary information from a PSI-BLAST search, and structure information from the first neural network. It was also trained on a set of sequences from the non-redundant database mentioned above, and achieved a Q3 score of 70% and a SOV score of 72%. It used a window size of 9, and was based on a 36-44-4 architecture. The Jury-of-experts program, which combined the results of the three stand-alone secondary structure predictions was also developed using Joone. It consisted of a standard feed-forward network containing a single hidden layer. Using a window size of 15, the structure annotations and confidence scores from each of the three methods (JNET, PSIPRED, and TRANSSEC) were used as input. Neural Network TrainingThe neural net was trained on 100 sequences chosen randomly from the non-redundant database mentioned above. Four output nodes were used, one for each of helix, strand or coil, as well as a fourth denoting the beginning and end of the sequence. A back-propagation training procedure was applied to optimize the network weights. A momentum term of 0.2 and a learning rate of 0.3 were used, and a second test set of 20 proteins was applied at the end of each epoch, to ensure that the network was trained for the most optimal number of iterations.Merging the homologous sequence with a predictionIf a homologous sequence was found whose sequence did not cover the entire length of the query sequence, then it was necessary to merge the homologous structure with that of the predicted structure. Though some secondary structure is the result of global interactions (hydrogen bonding between different parts of the sequence), homologous regions likely have similar local structure. Given that a homologous structure is likely to be more correct than the predicted structure, the homologous structure is mapped directly onto the predicted structure, replacing the states of the predicted structure with the homologous structure (Figure 3). |